OneDrive(以前のSkyDrive)は、あらゆるデータを7GBの共有スペースに保管、参照、管理できるクラウドサービスです。
PC、Mac、タブレット、スマートフォンなどのデバイスを利用して、どこからでも無料で写真、動画、ドキュメントなどのファイルを簡単に保存できます。
OneDriveへアップロードしたデータは、ワードプレスへ埋め込みができるので、ファイルをオープンせずに内容を参照することができます。
また、ファイル名や説明文などを付加すれば、該当のデータを簡単に検索することができます。
検索キー:書類送付ご案内
検索キー:秘密保持に関する誓約書
最近のOCRソフトには、PDFやテキスト以外にオフィス系アプリ(ワード、エクセル、パワーポイント)へ保存できるものが沢山あります。
しかし、オフィス系アプリへ変換を行い、すぐに利用できるほど変換精度の高いOCRソフトはほとんどありません。
チェック・修正、特にレイアウト等の修正に膨大な時間をかけるくらいならば、最初から作り直した方がマシではないか…というケースも決して少なくありません。
そこで、お勧めしているのは「OCRかけっぱなし」と「しおりの自動付加」です。
これならば、全文検索としおりの活用ができ、納期面・コスト面共に納得いただけるのではないでしょうか。
もう少し検索の精度を高めたいならば、見出しレベル(章・節・項…)だけチェック・修正を行うという方法があります。
また、文字化けやあきらかな読取りエラーだけ修正する方法もあります。
「e.Typist」には全文解析という機能があり、疑わしい語句だけ拾い出すことができます。
これはワードの校正ツールに似たものですが、「読んde!!ココ」や「読取革命」等他のOCRソフトにはない機能です。
「e.Typist」には、全文解析以外に置換リストという機能もあり、これは置換前、置換後の文字列をテキストデータとして保存し、一括で置換を行うことができます。
これらのツールを活用すれば、それほど手間をかけずにある程度の品質向上が図れます。
どうしてもオフィス系のデータとして再利用したい場合には、テキスト、図、表の各要素に分類して、テキストデータ、イメージデータ、エクセルデータとして完成させた後に、オフィス系アプリへ統合する方法があります。
いきなりオフィス系アプリ(ワード、エクセル、パワーポイント)に変換して、チェック・修正、レイアウト修正を行うよりは、いくらかは作業が軽減できると思います。
いずれにしても、どこまで時間とコストを捻出できるのかによるのではないでしょうか。
ADF付きスキャナの場合、断裁済みの原稿を読み込むので、元々曲がりが発生しにくい上、スキャナ自体に曲がり補正機能を有していることがあります。
そのため、敢えて曲がり補正(水平補正)を意識することは少ないかも知れません。
一方、手置きスキャナ(フラットベッドスキャナ)の場合は、ほぼ100%曲がりが発生するので、曲がり補正(水平補正)の工程は必須と言って良いでしょう。
しかし、曲がり補正ができるソフトウェアは意外に少なく、これまでは「読んde!!ココ」の曲がり補正を利用することがありました。
ところが、「読んde!!ココ」のPDF保存に問題があることが判ったため、さてどうしたものか…と思っていました。
その後、アクロバットXIに曲がり補正の機能があることに気が付きました。
「ゆがみ補正」という名称で、少々判りにくい場所にあります。
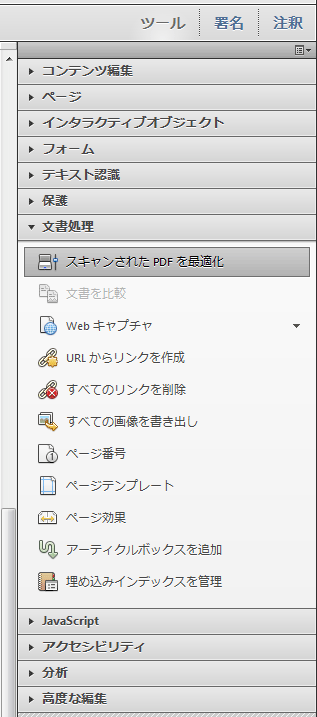
ツール→スキャンされたPDFを最適化→フィルター→ゆがみ補正
ゆがみ補正を「オン」にすると、PDFの曲がりを補正してくれることが判りました。
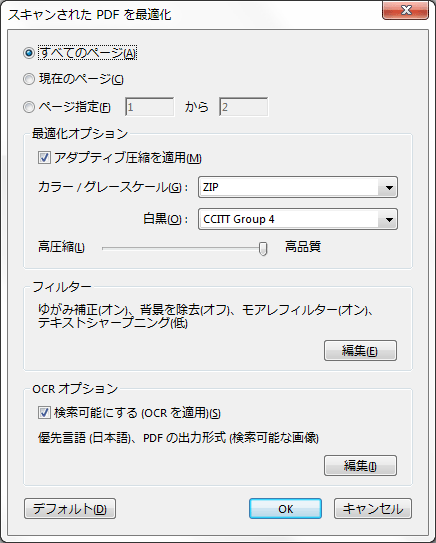
アクロバットのオンラインヘルプによると、最適化オプションのアダプティブ圧縮を適用とは、「各ページを白黒、グレースケール、カラーの領域に分割し、種類別に高い圧縮率で圧縮する一方で、見た目をほとんど変えずに表示します。」とありますので、チェックを入れておいた方が良いでしょう。
カラー/グレースケールについては、JPEG2000、ZIP、JPEGの3種類がありますが、どれも「圧縮をカラー画像コンテンツに適用します。」としか記述がないので、最も画質の劣化が少なそうなZIPを選択します。
白黒は、JBIG2(劣化なし)、JBIG2(劣化あり)、CCITT Group 4の3種類があります。JBIG2(劣化なし)はCCITT Group 4よりも60%の高圧縮が可能ですが、処理速度の低下、品質の劣化、Acrobat 5.0(PDF 1.4)以前のデータとの非互換等があるため、CCITT Group 4の選択をお勧めします。
高圧縮/高品質は、ファイルサイズの圧縮率と画質のバランスを設定します。
画質が気になる場合は、高品質にしておくのが無難かも知れません。
ゆがみ補正は、「スキャナーのガラス面の両端に対してページが平行に置かれていない場合、スキャンで生成されるPDFページがまっすぐになるように傾きを補正します。」とあり、これが曲がり補正(水平補正)のオプションであることが判ります。「オン」または「オフ」を選択します。
背景を除去の説明は次の通りです。
グレースケール画像やカラー画像を取り込むときに、白に近い色を白くします(白黒の画像には影響しません)。最適な結果を得るには、通常の白黒ページのテキストが濃い灰色または黒で、背景が白になるように、スキャナーのコントラストと明るさの設定をキャリブレーションします。次に、オプションを「オフ」または「低」にすると、適切な結果が得られます。オフホワイトの用紙または新聞用紙の場合は、「中」または「高」を選択します。
デフォルトは「オフ」です。
モアレフィルターの説明は次の通りです。
JPEG圧縮率を低下させ、モアレパターンを生じ、テキストを読みづらくする原因となるハーフトーンのドットを削除します。200~400dpiのグレースケール画像かRGB画像に適しています。また、アダプティブ圧縮の場合、400~600dpiの白黒画像に適しています。「オン」の設定(推奨)は300dpi以上のグレースケール画像とRGB画像のフィルターに適用します。 画像や塗りつぶされた領域がないページをスキャンするとき、または有効な範囲より高い解像度でスキャンするときは、「オフ」を選択します。
デフォルトは「オン」です。
テキストシャープニングの説明は次の通りです。
スキャンされたPDFファイルのテキストを鮮明にします。デフォルト値の「低」が多くの文書に適してします。印刷された文書の品質が低く、テキストが不明瞭な場合は「中」または「高」にあげます。
デフォルトは「低」です。
「読んde!!ココ」はOCRソフトですが、スキャン画像の傾き補正機能だけを使用することもできます。
単ページはもちろんですが、左右見開きページの傾き補正もできるので大変重宝しています。
自動傾き補正の機能がなかなか強力なので、大量のデータ処理が必要な時など、OCRファクトリーを使ってフォルダ単位に一括でスキャン画像の傾き補正を行うことができます。
また、白黒、カラー共に傾き補正後の品質劣化が少ない点もメリットとして挙げられると思います。
難点としては、PDFの読み込み、書き出しに時間がかかることと、保存するPDFのファイルサイズが大きくなることです。
しかし、意外な問題点が発覚しました。
保存するPDFのファイルサイズが大きいことには気付いていましたが、XEROXやキャノン、シャープ等のスキャナで作成するPDFは独自の圧縮技術を用いているので、「読んde!!ココ」で保存する際に圧縮が解除されているのかな?…くらいにしか考えていませんでした。
「読んde!!ココ」でPDF保存を行う場合、PDFのオプションは選択することができません。
まさか、白黒モードがRGBモードのPDFに変わっているとは考えもしませんでした。
納品後にお客様から指摘を受けた時は、本当に背筋に悪寒が走りました。
次に、RGBモードのPDFを、品質を劣化させずに白黒モードへ戻すにはどうすれば良いのか?…という問題に突き当たりました。
なかなか良い方法が見つからず困っておりましたが、フォトショップを使えばどうにかできそうだ…ということが判りました。
手順としては、まずPDFをアクロバットで単ページに分割し、次にフォトショップでRGBをグレースケールに落とし、さらにモノクロ2階調へ落とします。
その時、種類は「50%を基準に2階調に分ける」を選択します。
これらをアクションに記録し、フォルダ単位にバッチ処理を走らせました。
上記の処理を行い、RGBモードのPDFを白黒モードへ一括変換しました。
品質は残念ながら少々劣化しましたが、幸い許容範囲内でしたので事なきを得ました。
元々は私の確認不足が原因ではありますが、「読んde!!ココ」のPDF保存にはこのような問題点があるのでご注意ください。
スキャン対象がカラー原稿で、しかも仕上がりに高品質を求められる場合、断裁可・不可に関わらずADFは使わず手置きスキャナを使用しています。
白黒原稿ならばアクロバットのプラグインを使い、汚れや影の部分にマスク処理を施せば済みますが、カラー原稿の場合はフォトショップで補正を加える必要があります。
特に、原稿が断裁不可で用紙に厚みがあったり、ページ数が多いものは非常に厄介です。
左下の画像の様に、ページの中央付近に白っぽい帯状のテカりが出ることがあり、これを右下の画像のように目立たなく補正しなければなりません。


この補正処理は、なかなか手間がかかります。
良い方法はないか色々試行錯誤しておりますが、どうもこれといった決め手が見つかりません。
作業時間に見合ったコストをご負担いただければ良いのですが、なかなかそうも行きませんのでなるべく原稿の断裁をお願いしています。
フォトショップの機能を駆使すればある程度の時間短縮は可能ですが、要求品質の水準が高度な場合には少々無理が生じるかも知れません。
モニターで見る限り十分に高品質なレベルであり、なるべく手間をかけずリーズナブルなコストでのご提供を目指しております。
下の例などもよく見ると少々変ですが、品質・コスト・時間との兼ね合いということでご容赦ください。


文書をスキャンしてPDFを作成する場合、しおりを付けずに納品するケースがあります。その際、検索ができるようにOCR処理を行ない、透明テキスト付きPDFにします。
また、PDFを見出し単位に分割して保存し、見出しをエクセルに入力して、該当のPDFへハイパーリンク設定を行なう場合もあります。ハイパーリンクの設定は、VBA又はハイパーリンク関数を用いて行います。
次のケースは、エクセルに入力したしおり名、ページ、階層の情報を、しおりの付いていないPDFへ一括で付加する例です。JavaScriptを用いて、自動処理でPDFへしおりを付加します。
■階層なし(エクセル→PDF)
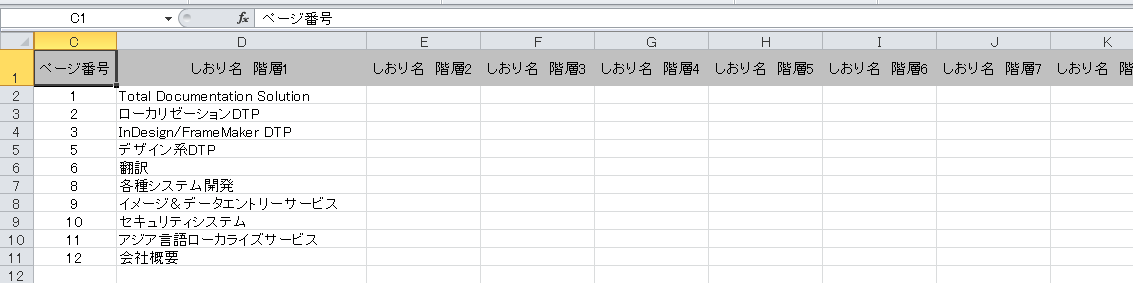
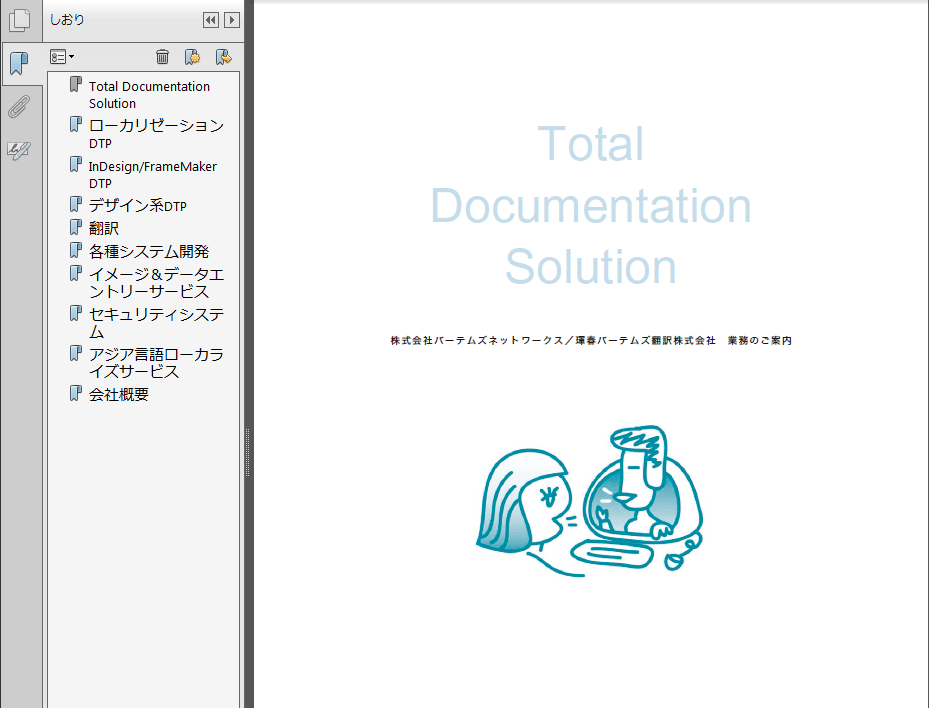
■階層あり(エクセル→PDF)

この方法ならば、これまでOCR処理しか行なっていなかったPDFへも、手間をかけずにしおりを付加できるので利便性の向上が図れ、PDFを分割したりハイパーリンク設定を行なう手間も省略できます。
また、しおり付きのPDFからしおりの情報を抽出し、HTMLへ書き出すことができます。HTMLのリンク先はPDFのしおりページです。
PDFを分割しなくても、該当のしおりページへリンクすることができます。
Webページやブログに組み込んでしおりページへリンクさせたり、目次ページを作成する等の使い方もできます。
一旦、しおりの情報をエクセルへ書き出してから、関数を使ってHTMLタグを付け加えています。
■階層なし(PDF→エクセル→HTML)

目次
Total Documentation Solution ….. P1
ローカリゼーションDTP ….. P2
InDesign/FrameMaker DTP ….. P3
デザイン系DTP ….. P5
翻訳 ….. P6
…
■階層あり(PDF→エクセル→HTML)
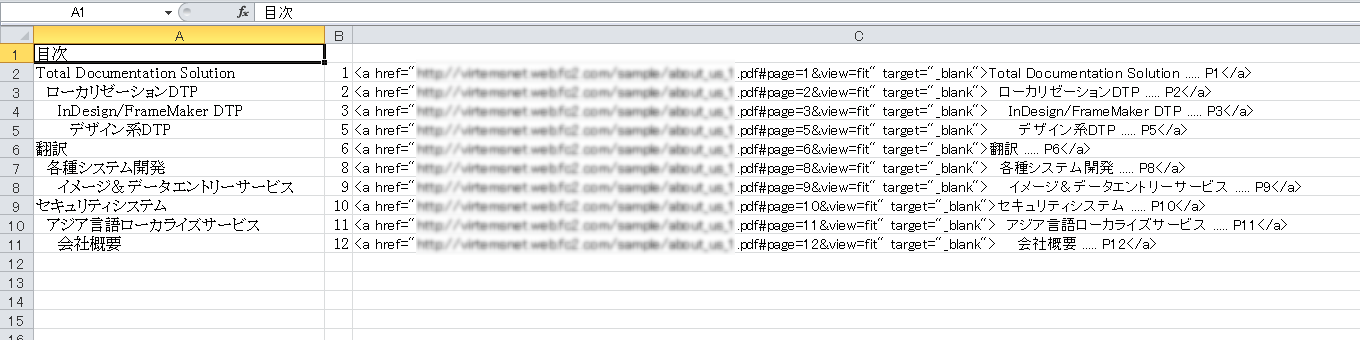
目次
Total Documentation Solution ….. P1
ローカリゼーションDTP ….. P2
InDesign/FrameMaker DTP ….. P3
デザイン系DTP ….. P5
翻訳 ….. P6
…
現在、日本語OCRソフトの種類は膨大にあり、フリーソフトやシェアウェア、PDF関連ツール等にもOCR機能を持つものが多数存在します。
ただ、良いOCRソフトは非常に少なく、概ね変換精度は低レベルと言わざるを得ない状況です。
そんな中、利用者が多く比較的評価の高いOCRソフトとして、「アクロバット」、「読んde!!ココ」、「読取革命」、「e.Typist」、「瞬簡PDF」の5種類は、まあまあお勧めできるかな…と思います。
しかし、上記5種類のOCRソフトでも、原稿の状態や特性によっては驚くほど読み取り精度が低下する場合があるので、現状の日本語OCRの水準はまだまだ発展途上ということなのだと思います。
OCR処理後、透明テキスト付きPDFに保存し、全文検索をかけて該当のキーワードがどうにかヒットするレベルでも納得できるのであれば、上記のOCRソフトでもほぼ問題ありません。
でも、もっと高精度を求める場合には、現状では人のチェック・修正という作業に頼らなければなりません。
もし、完璧にチェック・修正作業を行うと、始めから新規テキスト入力を行うのと変わらないくらいの時間とコストがかかってしまします。
これでは、OCRソフトを使用する意味が全くなくなってしまいます。
そこで、折衷案としてOCRかけっぱなし状態と完璧にチェック・修正を行う場合の中間、それなりにまともな状態に仕上げるというオプションをご提案します。
これは、OCRかけっぱなし状態のデータに対し校正ツールをかけ、明らかにおかしな箇所の周辺だけ重点的に修正を行うというものです。
校正ツールは、ワードのスペルチェックと文章校正が良さそうです。
大幅な時間短縮とそこそこの品質向上が図れ、テキストデータ又は透明テキスト付きPDFに保存できれば、それなりに有効なサービスになるのではないでしょうか。
これを実現するにはもう少し検証が必要ですが、コスト・納期の兼ね合いから、やや品質を犠牲にしても構わないというお客様には、ご検討いただけるサービスではないかと考えております。
しおりの読み込み(インポート)は、しおり付加作業の大幅な省力化及びPDFの使い勝手の向上という大きな改善効果が期待できます。
それでは、しおりの書き出し(エクスポート)にはどのようなメリットがあるのでしょうか?
すでにしおりが付加されているPDFをアクロバットで閲覧する場合には、敢えてしおりをテキストデータ等へ書き出すメリットはあまり無さそうです。
しかし、PDFがWebサーバー等に格納されていて、ネット経由でPDFのしおりへリンクしたい場合は、あらかじめしおりをテキストデータ等に書き出しておいて、ハイパーリンク設定を施して該当のしおりページへリンクする方法が考えられます。
HTMLからPDFのしおりページへリンクするには、しおり名とページ番号が必要になります。
しおり名とページ番号を書き出す方法は、「JUST PDF3(高度編集)」のエクスポートが便利です。
一旦、しおりページはPDFへ書き出されますが、後からエクセルの関数を用いてHTML用にタグ付けを行います。
この部分のワークフローは若干煩雑なので、もう少し改良を加える必要があります。
このように、しおりのインポートとエクスポートを行うことにより、PDFの活用の幅がさらに広がり、新たなサービスの提供へと繋がる可能性があるように思います。
実際に、PDFのしおりから作成したハイパーリンクの例です。
以下のリンク先は、PDFのしおりへダイレクトにハイパーリンクしています。
Total Documentation Solution ….. P1
ローカリゼーションDTP ….. P2
InDesign/FrameMaker DTP ….. P3
デザイン系DTP ….. P5
翻訳 ….. P6
PDFには、しおりという大変便利な機能があります。
しおりは、目次と同様の役割を持っており、ワードやエクセルなどのオフィス系アプリからPDFを作成する際には、自動的にしおりを付加することができます。
しかし、スキャン画像からPDFを作成する場合、後からアクロバットで一件ずつ入力しなければなりません。
アクロバットには、しおりを読み込んだり(インポート)、書き出したり(エクスポート)する機能がありません。
しおりのインポート・エクスポートができたら、もっと使い勝手が向上するのは間違いないでしょう。
そこで、PDFのしおりに関連する有料・無料のツールを色々と調べてみました。
ネットを検索してみると、フリーソフトやシェアウェア、製品版等が多数ヒットします。
JavaScriptを使って処理する方法もあるようですが、エクセルと連携できるものが良いと思いました。
エクセルにしおり名、リンクするページ、しおりの階層を指定するだけで、後はしおりを付加するPDFファイルを選択して実行すればOK!というシンプルな機能で十分です。
しおりの階層は10階層も指定できれば十分ではないでしょうか。
いくつか実務に使えそうなソフトがありました。
これまでしおりの付加は、アクロバットで一件ずつ入力、リンク設定を繰り返さなければならなかったので、それなりの時間とコストがかかるものという既成概念がありました。
これからは、ツールの有効活用により大幅な省力化が可能になります。
今後、時間とコストの問題からしおりの付加を見送っていたお客様にも、きっと満足していただけるしおり付きPDFをご提供できるのではないかと考えております。
下の表は、OneDrive(以前のSkyDrive)にアップロードしたエクセルを埋め込んだ例ですが、エクセルデータをワードプレスへ取り込む方法は何種類かあります。
主なものとしては、TablePress等のプラグインを使う方法、エクセルの表をコピー&ペーストする方法、MovableTypeの形式に書き出してインポートする方法等です。
注意点としては、エクセルデータはShift-JISコードで保存されるため、ワードプレスへ取り込むにはUTF-8コードにエンコードしなければならない点です。
TeraPadや秀丸等のテキストエディターで、UTF-8コードに変更してからワードプレスへインポートしないと文字化けが発生します。
検索キー:議事録
検索キー:見積書、納品書
検索キー:休日出勤届
手置きスキャン、見開きスキャン、非破壊スキャン、OCR、PDF関連サービスや、ワードプレスによるドキュメントデータベースサービスをご提供いたします。