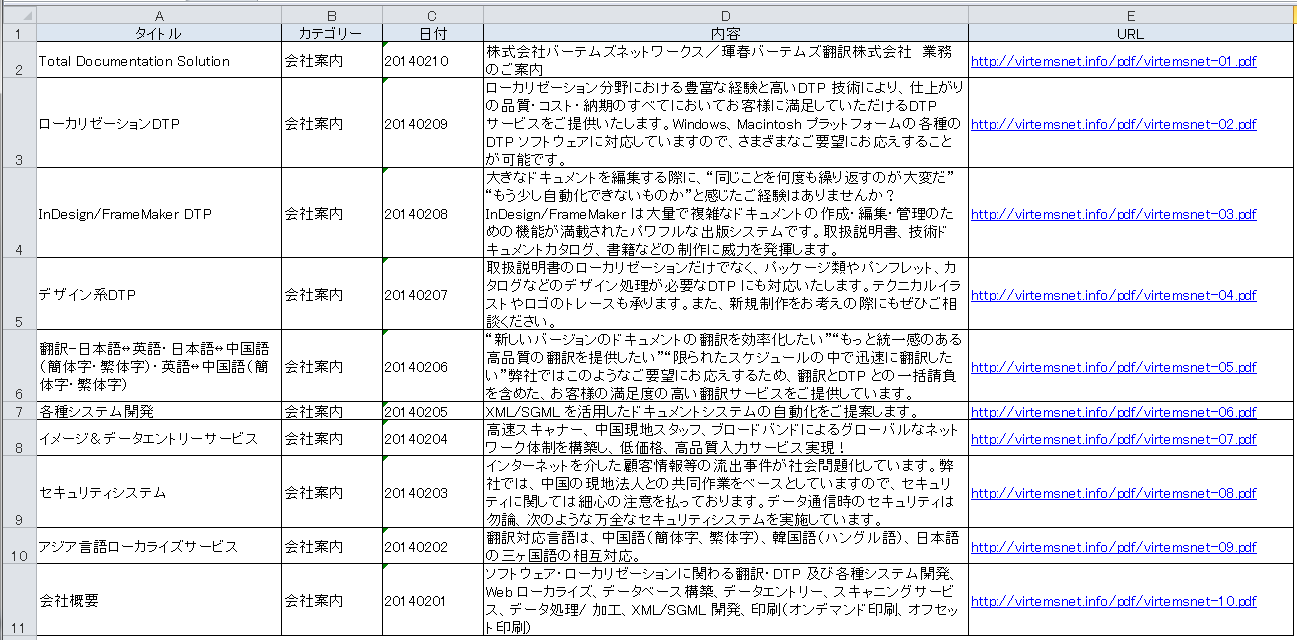
弊社の業務紹介をワードプレスにインポートしてみました。
このままインポートすることも可能ですが、今回は1行を1ページ(1記事)としてインポートするために多少手を加えました。
MovableType形式のテキストデータは、ツール > インポートから読み込みます。
この方法で読み込んだ結果が以下のページです。
ページめくりができるPDFのサンプルページです。
「速ワザ」は、しおり機能、オリジナルPDFのダウンロード機能等もあり、高性能の割には低価格なのでお勧めのアプリケーションソフトです。
> 業務案内 速ワザ 業務案内 aXmag 業務案内 issuu
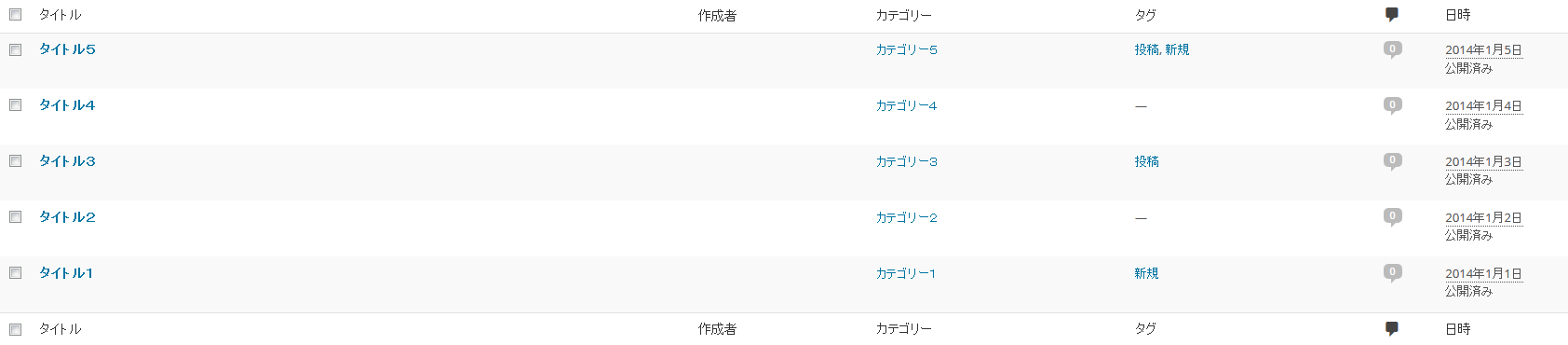
エクセルの表をワードプレスへインポートすることができます。
一括で大量のエクセルデータをインポートする場合に有効な方法です。
■ エクセルデータ(インポート前)
■ ワードプレス(インポート後)
以下は、Youtube の動画を埋め込みコードによりサイト内へ埋め込んだ例です。
以下は、Youtube の動画を埋め込みコードによりサイト内へ埋め込んだ例です。
これまでに携わった業務実績の一部を以下に記載しました。
業務名 作業内容
医学学会「学会誌」 約30000ペ―ジのスキャニング、検索用キーワード入力(論文タイトル、著者名、所属名、要旨等)
電子工学系学会「学会誌」 約50000ページのスキャニング、検索用キーワード入力(論文タイトル、著者名、所属名、要旨等)
情報処理系学会「学会誌」 約40000ページのスキャニング、書誌情報のテキスト入力・校正
研究機関「新聞」 約30000ページのスキャニング、検索キーワード入力(記事名、著者名、所属名、発行年月日等)
薬事情報申請/審査/報告書類 約10000ページのテキスト入力、XML化(DTD設計を含む)、印刷用PDF及びHTML自動生成のためのスタイルシート作成
研究機関「図書館の書誌情報」 入力用原稿のスキャニング作業、目次・書誌情報入力
自動車部品メーカー「標準化マニュアル」 約15000ページのスキャニング、Word編集(作図を含む)
建材メーカー「カラーカタログ」 約10000ページのカラースキャニング・画像補正、検索用キーワード入力
金融機関「業務マニュアル」 約10000ページのスキャニング、Word編集(作図を含む)
総合建築会社「標準仕様書」 テキスト入力、Word編集(作図を含む)
出版社「ビジネス情報誌DVD化」 約60000ページのカラースキャニング・画像補正
国土交通省「調査表」 データエントリー、集計分析票作成
東京都某外郭団体「アンケート」 データエントリー、集計分析票作成
国立大学某研究室「アンケート」 データエントリー、集計分析票作成
全国地方自治体「広報」 携帯電話向けテキスト入力・HTML作成
某議会「議会議事録」 約100000ページのスキャニング
建材/住宅機器「カタログ」 約300000ページのスキャニング、PDF最適化
自動車メーカー「カタログ」 約10000ページのスキャニング、PDF最適化
株式会社バーテムズネットワークス Virtems Networks Inc.
以下は、Youtube の動画を埋め込みコードによりサイト内へ埋め込んだ例です。
最近のOCRソフトには、PDFやテキスト以外にオフィス系アプリ(ワード、エクセル、パワーポイント)へ保存できるものが沢山あります。
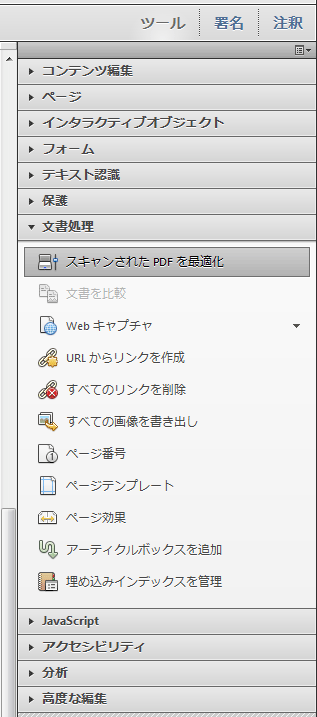
ADF付きスキャナの場合、断裁済みの原稿を読み込むので、元々曲がりが発生しにくい上、スキャナ自体に曲がり補正機能を有していることがあります。
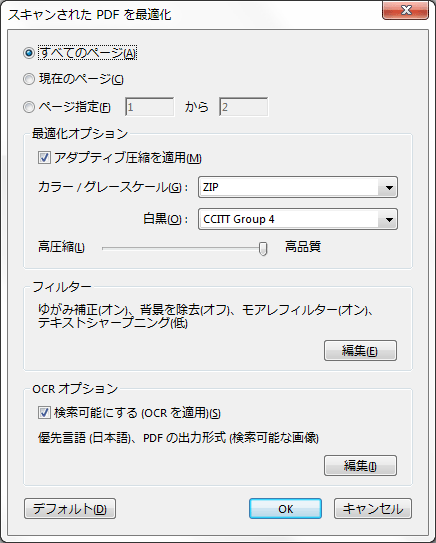
ツール→スキャンされたPDFを最適化→フィルター→ゆがみ補正
アクロバットのオンラインヘルプによると、最適化オプションのアダプティブ圧縮を適用とは、「各ページを白黒、グレースケール、カラーの領域に分割し、種類別に高い圧縮率で圧縮する一方で、見た目をほとんど変えずに表示します。」とありますので、チェックを入れておいた方が良いでしょう。
「読んde!!ココ」はOCRソフトですが、スキャン画像の傾き補正機能だけを使用することもできます。
投稿ナビゲーション
手置きスキャン、見開きスキャン、非破壊スキャン、OCR、PDF関連サービスや、ワードプレスによるドキュメントデータベースサービスをご提供いたします。